Chorus
Chorus is a vancomycin AUC simulator built around an ensemble, not a single model.
- — 46 models, fitted together. Bayesian MAP fit per model, combined by Bayesian model averaging, with per-model fit metrics.
- — Regimen simulation. Probability of hitting AUC/MIC and trough targets across the model ensemble, not a single yes/no.
- — Empiric Auto-Select. Before any levels exist, an ML layer ranks the 46 models by predicted fit from demographics alone.
- — Runs in your browser. De-identified by default; patient data never leaves your machine.
For Educational and Research Use Only. Chorus is an experimental simulator and is not a validated clinical tool. Do not use it for patient care or clinical decision-making. See the Terms.
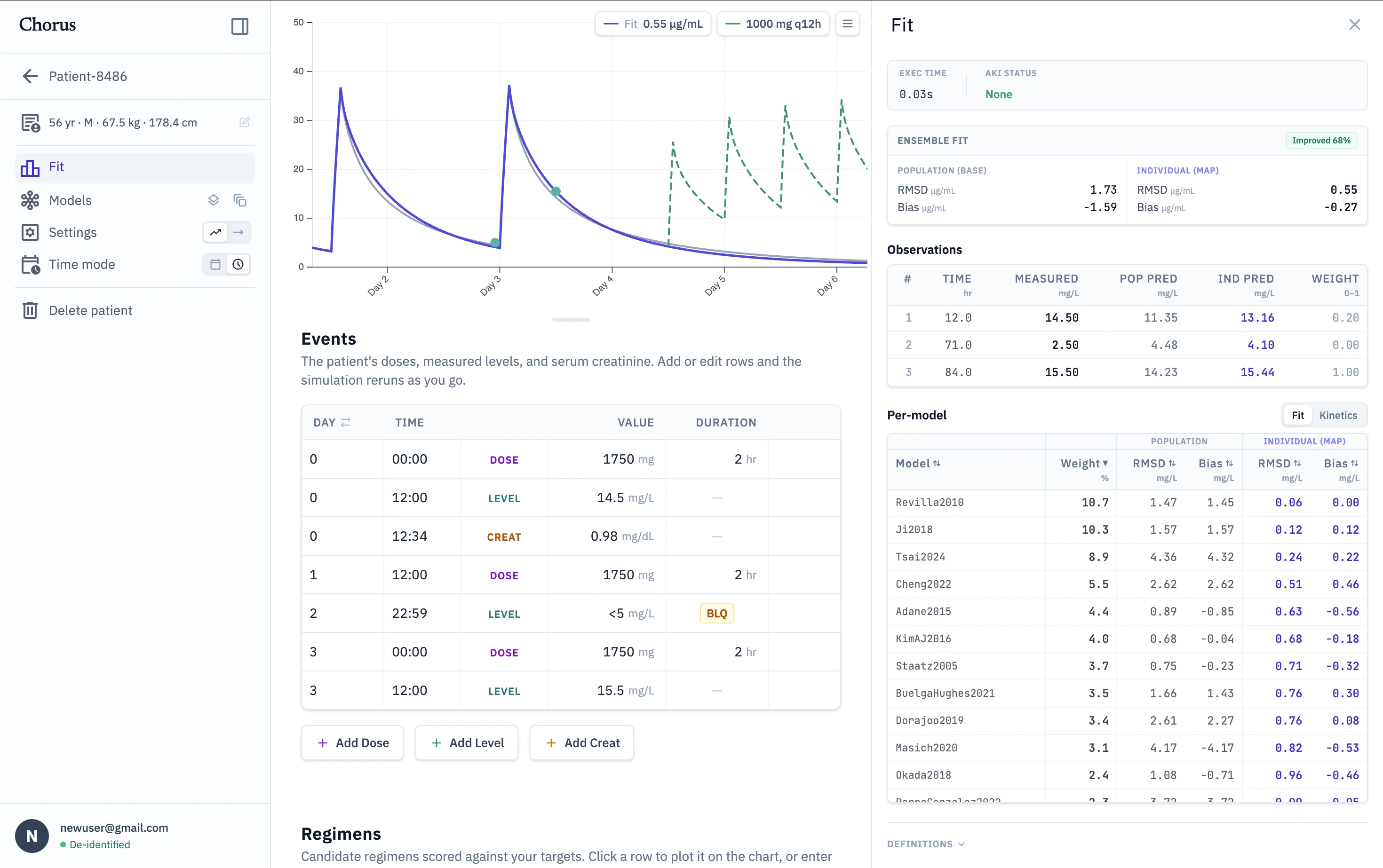
46 active population PK models, run in parallel
One-, two-, and three-compartment models
Renal function tracked over time from serial creatinine
Equal-weight, SSE-weighted, or SSE + overfitting penalty
RMSD / SSE / bias per model and aggregate
Weighted schemes after Uster et al., 2021
Dose / interval search against AUC/MIC and trough targets
Probability of target AUC, toxic trough, and effective trough
Or evaluate a specific regimen of your own directly
Ranks models by predicted accuracy, weighting the average toward the top picks
Every ranking explained by per-feature contributions (SHAP)
Trainable on your own patients, entirely on your machine
Selection target from van Os et al., 2025
Bayesian maximum a posteriori (MAP) estimation
Combined additive + proportional residual error model
Below-limit-of-quantification levels handled explicitly
KDIGO-style detection from the serum-creatinine series
Patient files saved to a folder you choose on your own disk
Nothing sent to a server, under any configuration
De-identified by default — HIPAA Safe Harbor, as if every input were PHI
Relative dates, ages over 89 capped to "90+"
Privacy & security for the full policy
Share one workspace folder across a team, on a shared drive
Per-patient locks keep two people from editing the same patient at once
Workspace-wide report of how each model fits across your patients
Numerical core written in Rust, compiled to WebAssembly
Full 46-model fit in under a second
Chrome or Edge on desktop — requires the File System Access API
Nate Van Veldhuizen, PharmD